The Ultimate Guide to Building a Data Warehouse from Scratch with Apache Stack
Table of contents
TABLE OF TIPS
Share this article on
In today’s data-driven world, businesses rely heavily on data to make informed decisions, gain competitive advantages, and drive growth. To harness the full potential of data, organizations often require a robust data warehousing solution. In this guide, you’ll learn a 7-step framework to design and implement a Data Warehouse using Apache Stack (Spark, Hadoop, Hive), including architecture design, ETL workflows, and performance best practices.
Benefits and limitations of Apache stack?
Apache Stack is a concept commonly used to refer to a collection of open-source software and tools developed and maintained by the Apache Software Foundation (ASF). These tools are commonly used to build and manage web applications, network services, and online data systems. Here are some important pros of Apache Stack
Cost-effectiveness: Because Apache Stack is open source, license expenses are reduced.
Scalability: It allows for the handling of increasing data quantities.
Apache Stack is very adaptable and configurable.
It has quick data processing and analytics capabilities.
Resource usage is optimized with Apache Stack.
Advanced analytics are supported using technologies such as Apache Spark.
Open-Source Community: Take use of a large open-source community for help and creativity.
It cannot be denied that Apache offers us numerous advantages. However, there are some small constraints that I want to highlight in this article for a two-sided perspective
There is no automatic optimization process, thus performance must be optimized manually.
Small File Problem: Small files might cause problems with storage efficiency.
Not Recommended for Multi-User Environments: It may not be appropriate for sophisticated multi-user settings.
4 reasons to build a data warehouse with Apache stack?
Building a data warehouse with the Apache Stack is a strategic move that comes with a multitude of benefits. This open-source distributed computing platform has gained immense popularity in recent years, largely due to its versatility, scalability, and robustness. Let’s delve deeper into the advantages of using the Apache Stack for your data warehousing needs
1. Open-Source Power
The Apache Stack’s open-source nature is one of its most notable advantages. This means you may tap into the collective wisdom of a large community of developers and users who contribute to and support the ecosystem. Open-source solutions are typically less expensive and more flexible than proprietary ones.
2. Spark’s Popularity
Apache Spark, a key component of the Apache Stack, is well-known for its speed and capacity to handle large amounts of data. It provides a complete suite of data processing, machine learning, and graph analytics frameworks and APIs. Spark’s prominence in the data science and big data communities provides plenty of resources and knowledge, making it a top choice for enterprises looking for sophisticated analytics capabilities.
3. Hadoop for Data Extraction
Another essential member in the stack, Apache Hadoop, specializes in data extraction from huge and complicated datasets. It stores data across a cluster of machines using a distributed file system (HDFS) and then processes and analyzes it using MapReduce. As a result, it is an excellent solution for enterprises dealing with large amounts of data, such as clickstream data, logs, and sensor data, a leading choice for businesses looking for advanced analytics capabilities.
4. Efficient and Reliable Hive
Hive is a data warehousing and SQL-like query language system that operates on top of Hadoop. It provides a familiar interface for data analysts and SQL developers, making it easier for them to work with big data. Hive optimizes queries and translates them into MapReduce jobs, delivering impressive performance improvements over raw MapReduce. Moreover, Hive is known for its efficiency and reliability, ensuring consistent and accurate results in data warehousing operations.
7 steps to build a data warehouse from scratch with Apache stack?
Step 1: Goals Elicitation
🔹Discovery of Business Objectives
The journey of building a data warehouse begins with understanding your business objectives. What are your tactical and strategic goals? Knowing these will guide your data warehousing efforts.
🔹Identification and Prioritization of Needs
Identify and prioritize the specific requirements from various projects within your organization. These needs will help define the scope of your data warehouse.
🔹Preliminary Data Source Analysis
Conduct a comprehensive analysis of your data sources. To establish how to manage data, you must first understand its structures, volumes, sensitivities, and other characteristics to determine how to handle them.
🔹Outlining Scope & Security Requirements
Clearly define the scope of your data warehouse and establish security requirements. Data security is paramount in today’s regulatory environment, and outlining these requirements early is essential.
Step 2: Conceptualization and Platform Selection
🔹Defining the Desired Solution
Once your goals are clear, define the desired data warehouse solution. Consider factors like data accessibility, performance, and scalability.
🔹Choosing the Optimal Deployment Option
Decide whether you want to deploy on-premises, in the cloud such as AWS, Azure, or in a hybrid environment. This choice will impact your architectural design.
🔹Optimal Architectural Design
Select the best architectural design based on your goals and deployment choice. Consider factors like data volume, complexity, and expected growth.
🔹Selecting Data Warehouse Technologies
Choose the appropriate Apache Stack technologies based on your needs, including the number and volume of data sources, data flow requirements, and data security considerations.
Step 3: Business Case and Project Roadmap
🔹Defining Project Scope and Timeline
Create a detailed project scope, timeline, and roadmap for your data warehouse development. This will help you manage expectations and resources effectively.
🔹Scheduling Activities
Schedule activities for designing, developing, and testing your data warehouse. Estimate the effort required for each phase.
Step 4: System Analysis and Data Warehouse Architecture Design
🔹Detailed Data Source Analysis
Perform a detailed analysis of each data source, considering data types, volumes, sensitivity, update frequency, and relationships with other sources.
🔹Designing Data Policies
Create data cleansing and security policies to ensure data quality and protect sensitive information.
🔹Designing Data Models
Develop data models that define entities, attributes, and relationships. Map data objects into the data warehouse.
🔹ETL/ELT Processes
Design ETL/ELT processes for data integration and flow control. Ensure seamless data movement and transformation.
Step 5: Development and Stabilization
🔹Platform Customization
Customize your data warehouse platform according to your requirements.
🔹Data Security Configuration
Configure data security software to enforce access controls and encryption.
🔹ETL/ELT Development and Testing
Develop ETL (Extract – Transform – Load) / ELT (Extract – Load – Transform) pipelines and thoroughly test them to ensure data accuracy and reliability.
Step 6: Launch
🔹Data Migration and Quality Assessment
Migrate data into the data warehouse and assess its quality. Identify and address any issues.
🔹Introducing to Users
Introduce the data warehouse to business users, ensuring they understand how to access and leverage the data.
🔹User Training
Conduct user training sessions and workshops to empower your team to make the most of the data warehouse.
Step 7: Post-Launch Support
🔹Performance Tuning
Monitor and optimize ETL/ELT performance to maintain data warehouse efficiency.
🔹Adjusting Performance and Availability
Make adjustments to ensure the data warehouse meets performance and availability expectations.
🔹User Support
Provide ongoing support to end users, helping them address any issues or queries.
Data warehouses serve multiple critical functions in a business context, including facilitating strategic decision-making, aiding in budgeting and financial planning, supporting tactical decision-making, enabling performance management, handling IoT data, and serving as operational data repositories. When executed effectively, data warehousing can deliver significant value to a company.
Building a data warehouse for your organization requires a skilled team comprising a project manager, business analyst, data warehouse system analyst, solution architect, data engineer, QA engineer, and DevOps engineer. Instead of opting for an in-house development team, which may incur substantial costs, consider leveraging the expertise of ITC Group. We offer a seasoned team of developers experienced in data warehouse to develop custom software solutions at a reasonable price point.
Real Implementation Guide: Building a Production-Ready Data Warehouse with Apache Stack
1. Reference Architecture for Apache-Based Data Warehouse
A production-ready data warehouse built with Apache technologies typically follows a layered architecture:
🔹 Layer 1 – Data Ingestion
Data is ingested from:
Relational databases (MySQL, PostgreSQL)
SaaS APIs (Salesforce, HubSpot)
Log streams
CSV/JSON batch files
Tools:
Apache Kafka (real-time ingestion)
Apache Sqoop (RDBMS ingestion)
REST connectors or custom ingestion services
🔹 Layer 2 – Storage (Data Lake on HDFS)
Raw data is stored in HDFS using structured formats such as:
Parquet (columnar, optimized for analytics)
ORC (Hive-optimized columnar format)
Example directory structure:
Partitioning strategy example:
Partition by year/month/day
Partition by region for geo-based analytics
🔹 Layer 3 – Processing (Apache Spark ETL)
Spark transforms raw data into analytics-ready datasets.
Key transformations:
Data cleansing
Deduplication
Schema validation
Aggregation
Business metric calculation
🔹 Layer 4 – Serving Layer (Hive / BI Tools)
Processed datasets are exposed via:
Apache Hive (SQL interface)
Presto / Trin
BI tools (Power BI, Tableau)
2. Sample Spark ETL Implementation
Below is a simplified Spark ETL example in PySpark:
What This ETL Job Does:
Loads raw Parquet files
Removes null records
Deduplicates orders
Aggregates revenue by region
Writes partitioned output for fast querying
3. Spark Performance Configuration Sample
Production Spark jobs require tuning for performance.
Example configuration:
Key Optimization Principles:
Avoid small files problem
Optimize shuffle partitions
Use broadcast joins when possible
Cache frequently reused datasets
Monitor with Spark UI
4. Hive Table Optimization Example
Example Hive external table using Parquet:
After creating table:
Hive Performance Tips:
Use partition pruning
Avoid SELECT *
Enable vectorized execution
Use ORC/Parquet
Maintain statistics
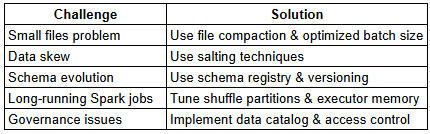
Common Implementation Challenges & Solutions
Frequently Asked Questions
What is a Data Warehouse in the Apache ecosystem?
A Data Warehouse in the Apache ecosystem is a centralized storage system built using technologies such as Apache Hadoop, Apache Spark, and Apache Hive. It enables large-scale data storage, transformation, and analytical querying for business intelligence and reporting.
What components are typically included in an Apache Stack for Data Warehousing?
A typical Apache-based data warehouse architecture includes:
Hadoop (HDFS) for distributed storage
Spark for data processing and ETL/ELT
Hive for SQL-based querying
Kafka (optional) for real-time ingestion
Airflow or Oozie for workflow orchestration
What is the difference between ETL and ELT in Apache-based systems?
ETL (Extract, Transform, Load) processes and transforms data before loading it into the warehouse.
ELT (Extract, Load, Transform) loads raw data first and performs transformations inside the data warehouse using engines like Spark or Hive.
ELT is often preferred in modern big data architectures because distributed processing engines can handle transformations efficiently at scale.
How do you design a scalable Data Warehouse architecture?
To design a scalable data warehouse:
Define business requirements and KPIs
Choose batch vs real-time architecture
Select appropriate storage formats (Parquet, ORC)
Optimize partitioning strategies
Implement proper data governance and monitoring
How can performance be optimized in Apache Hive?
Performance optimization techniques include:
Partitioning and bucketing tables
Using columnar formats (Parquet/ORC)
Enabling predicate pushdown
Tuning Spark execution parameters
Proper indexing and statistics gathering
Is Apache Stack suitable for real-time analytics?
Yes, when combined with tools like Kafka and Spark Streaming, Apache Stack can support near real-time data ingestion and processing. However, architecture decisions depend on latency requirements and workload scale.
What are common challenges when building a Data Warehouse from scratch?
Stay ahead in a rapidly changing world with our monthly look at the critical challenges confronting businesses on a global scale, sent straight to your inbox.
Stay ahead in a rapidly changing world with our monthly look at the critical challenges confronting businesses on a global scale, sent straight to your inbox.
Subscribe for our latest insights!
Stay ahead in a rapidly changing world with our monthly look at the critical challenges confronting businesses on a global scale, sent straight to your inbox.
Thank you for subscribing!
You’ve been added to our list and will hear from us soon.
Your choice regarding cookies on this site
Some of these cookies are essential, while others help us to improve our services and your experience by providing insights into how the site is being used. Click to View Our Cookie Policy
Manage my preferences
We use cookies to help you navigate efficiently and perform certain functions. You will find detailed information about all cookies under each consent category below. The cookies that are categorized as "Necessary" are stored on your browser as they are essential for enabling the basic functionalities of the site. We also use third-party cookies that help us analyze how you use this website, store your preferences, and provide the content and advertisements that are relevant to you. These cookies will only be stored in your browser with your prior consent. You can choose to enable or disable some or all of these cookies but disabling some of them may affect your browsing experience.
Necessary
These essential Cookies enable seamless access to our Sites, recognizing logged-in accounts and recent interactions for improved user experience and Site security. They are crucial for site functionality, triggered by service-related actions. While browser settings can block them, some site features may be affected. Importantly, these cookies don't store personal info.
Functional
These Cookies remember your choices and user details for seamless site operation, including personalized settings. They also enhance functionality and may be from third-party providers. Blocking them could limit certain services.
Analytics & Performance
These Cookies analyze site usage and performance. They track popular pages, visitor locations, and can be linked to your profile if you subscribe or register. These cookies count visits, show page popularity, and gather anonymous data on visitor movement, crucial for improving site performance. Without them, we can't track visits or monitor site performance
Advertisement
These cookies create an interest profile of yours, subsequently displaying pertinent advertisements on other websites. These cookies rely on unique identifiers linked to your browser and internet device, rather than storing personal information directly. By opting not to permit these cookies, you will encounter reduced levels of targeted advertising.